老师教你解决线上BUG的思路
推荐
在线提问>>
一. 问题再现
在做某个金融项目时,其中有个服务的流程组水平分库上线后,导致我们组的 xxx-app gc时间过长,在这个机器上 2021-01-26T00:00:00.000+0800 - 2021-01-26T11:00:00.000+0800 gc时间超过1s有482次。

二. 异常分析
2.1 gc日志
我们来查看一下线上服务器的日志文件:
cat gc.log.* |grep 'Total time for which application threads'|grep '2021-01-26T'|awk 'BEGIN{FS=" "} { if ($11 > 1) print $0}'|wc -l
观察了这台服务器上的gc日志,发现gc时间超过1s的gc,gc时间都消耗在Scan RS阶段
2021-01-26T12:45:47.366+0800: 399301.151: Total time for which application threads were stopped: 0.0292893 seconds, Stopping threads took: 0.0004658 seconds 2021-01-26T12:45:47.398+0800: 399301.183: [GC pause (G1 Evacuation Pause) (mixed), 2.0761779 secs] [Parallel Time: 1980.3 ms, GC Workers: 8] [GC Worker Start (ms): Min: 399301184.2, Avg: 399301185.7, Max: 399301186.1, Diff: 1.9] [Ext Root Scanning (ms): Min: 7.1, Avg: 10.3, Max: 12.8, Diff: 5.7, Sum: 82.5] [Update RS (ms): Min: 23.7, Avg: 25.4, Max: 30.9, Diff: 7.3, Sum: 203.6] [Processed Buffers: Min: 14, Avg: 38.4, Max: 76, Diff: 62, Sum: 307] [Scan RS (ms): Min: 1912.8, Avg: 1918.6, Max: 1924.0, Diff: 11.2, Sum: 15349.1] [Code Root Scanning (ms): Min: 0.0, Avg: 1.0, Max: 6.8, Diff: 6.8, Sum: 8.2] [Object Copy (ms): Min: 17.5, Avg: 22.8, Max: 24.8, Diff: 7.2, Sum: 182.7] [Termination (ms): Min: 0.0, Avg: 0.2, Max: 0.2, Diff: 0.2, Sum: 1.2] [Termination Attempts: Min: 1, Avg: 86.1, Max: 113, Diff: 112, Sum: 689] [GC Worker Other (ms): Min: 0.0, Avg: 0.1, Max: 0.1, Diff: 0.1, Sum: 0.5] [GC Worker Total (ms): Min: 1978.1, Avg: 1978.5, Max: 1980.0, Diff: 1.9, Sum: 15827.8] [GC Worker End (ms): Min: 399303164.2, Avg: 399303164.2, Max: 399303164.2, Diff: 0.0] [Code Root Fixup: 0.1 ms] [Code Root Purge: 0.0 ms] [Clear CT: 1.3 ms] [Other: 94.5 ms] [Choose CSet: 0.3 ms] [Ref Proc: 82.9 ms] [Ref Enq: 0.5 ms] [Redirty Cards: 7.6 ms] [Humongous Register: 0.1 ms] [Humongous Reclaim: 0.0 ms] [Free CSet: 0.5 ms] [Eden: 396.0M(396.0M)->0.0B(396.0M) Survivors: 12.0M->12.0M Heap: 5583.9M(8192.0M)->5181.2M(8192.0M)] [Times: user=15.91 sys=0.00, real=2.07 secs] 2021-01-26T12:45:49.475+0800: 399303.260: Total time for which application threads were stopped: 2.0895828 seconds, Stopping threads took: 0.0019140 seconds 2021-01-26T12:45:49.488+0800: 399303.273: Total time for which application threads were stopped: 0.0107491 seconds, Stopping threads took: 0.0003724 seconds
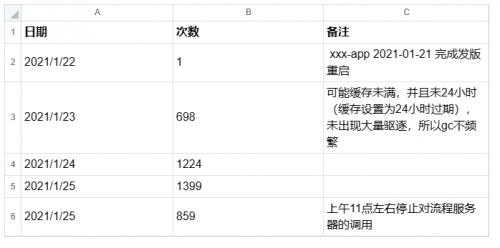
xxx-app 机器 gc 超过1s 的次数按天统计,以下是每天的次数统计表:
2.2 jvm内存的内容
停止xxx-app服务器上的服务,把内存dump下来分析,情况如下图所示:
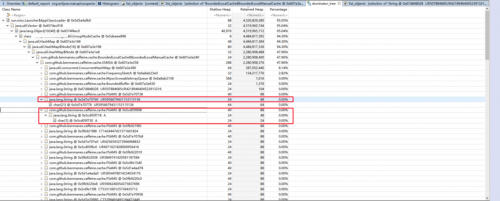
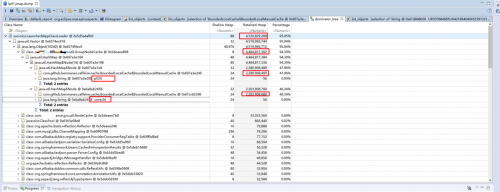
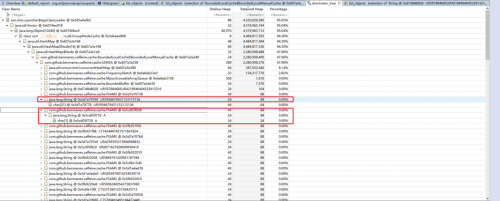
由上面的图可以得到下面的数据:
cache使用内存4.5G左右,pf和core组各占2.2G左右,每个group最大存储数量为1千万的key value对,由图可以看到key和value一共2千万,已经到了最大值。 每个key 88字节,每个value 88字节,则1千万的key value对占用内存10000000*88byte=1.67G。再加上387M的map结构,134M的频率统计数组,1.67G+387M+134M大致等于2.2G。
2.3 原因猜测
那到底是什么原因导致了以上这些问题呢?猜测有如下原因:
缓存对象太多了,pf和core 1千万的缓存,key + value 就4千万对象,总共占4G内存。这些key和value分布在不同Region,可能有互相引用,导致RSet很大,Scan RS时间长。
三. 解决办法
既然现在百泽对以上故障有了大致的猜测方向,我就按如下思路进行解决。
3.1 部分机器缓存关停验证
在xxx-app增加apollo开关,可以关停指定goup的缓存,通过apollo的灰度发布关停部分机器的缓存,观察这些机器是否gc是正常,redis访问次数是否突增。如果gc正常,对redis访问量增加不大,可以考虑取消java内存缓存
3.2 -XX:G1RSetRegionEntries 参数调整
Scan RS 时间过长,官方文档推荐调整G1RSetRegionEntries参数,但是具体调整成多少,需要根据服务器的相关调整。 下图是官方文档的说明,大致意思是如果RS时间过长可以跳转该参数





